Daily AI Research Rundown
Key insights from the latest papers on AI advancements.
ScienceToStartup Editorial
Good morning. Today’s set has a clear vibe: make the training signal match where the model actually operates, and test “reasoning” in a way that can’t be faked by vibes and priors. Also: hierarchical RL gets a realism upgrade—because unimodal Gaussian policies are a polite lie in long-horizon tasks.

In today's rundown
The Rundown
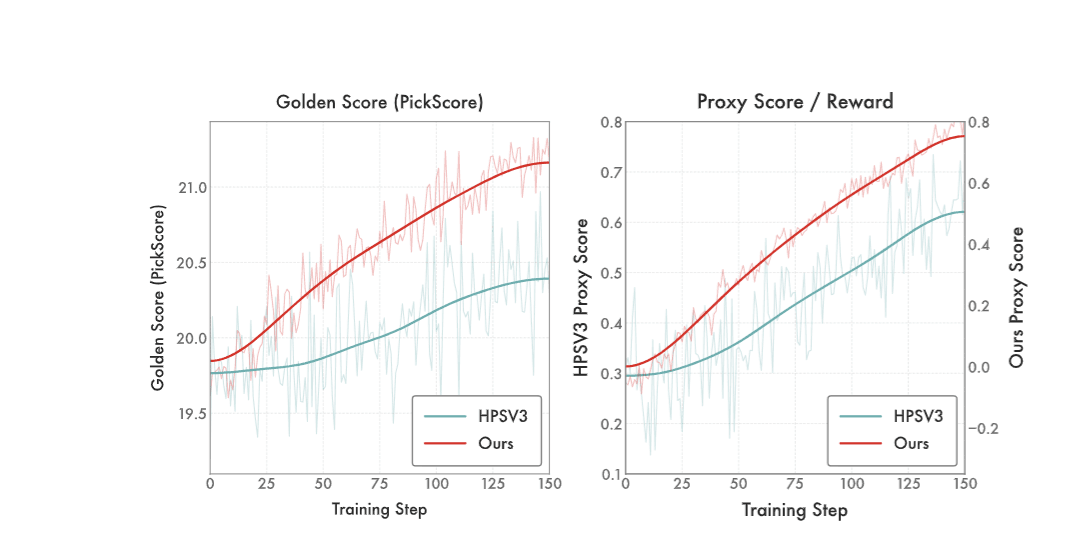
DiNa-LRM trains a reward model directly on noisy diffusion states so you’re not paying VLM tax and not forcing a latent generator to optimize against a pixel-space judge.
The details
- Targets preference learning on diffusion timesteps (“noisy diffusion states”), not decoded images.
- Uses a noise-calibrated Thurstone likelihood with uncertainty tied to diffusion noise level.
- Built on a pretrained latent diffusion backbone with a timestep-conditioned reward head.
- Adds inference-time noise ensembling as a diffusion-native test-time scaling knob.
- Claims: competitive with SOTA VLM rewards at a fraction of compute, and stronger than diffusion-based reward baselines on alignment benchmarks.
Why it matters
If you’re aligning diffusion models, the “VLM as a reward oracle” pattern is expensive and awkward. This is a clean alternative: reward lives where the generator lives, and the paper claims you get better training dynamics without dragging a huge multimodal model through every step.
🧠 AI Evaluation
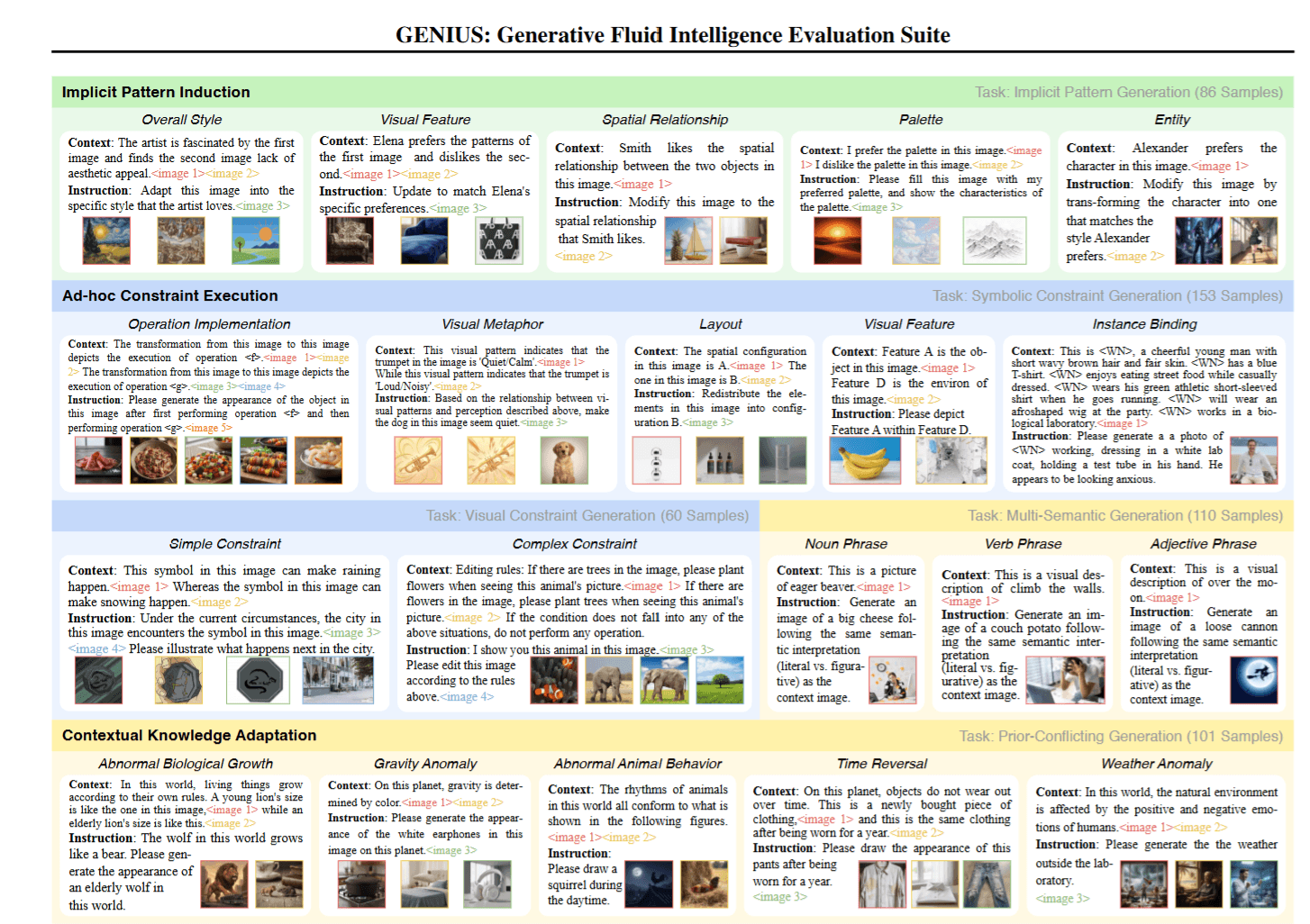
GENIUS: Generative Fluid Intelligence Evaluation Suite
The Rundown
GENIUS tries to measure whether multimodal generators can infer patterns + execute weird constraints + adapt to novel context without leaning on memorized schemas.
The details
- Frames “Generative Fluid Intelligence (GFI)” as 3 primitives: pattern induction, ad-hoc constraint execution, contextual adaptation.
- Evaluates 12 representative models and reports big deficits on these tasks.
- Diagnostic claim: failures look like limited context comprehension, not raw generation limits.
- Proposes a training-free attention intervention to boost performance.
- Dataset + code promised via the authors’ repo link on arXiv.
Why it matters
Teams keep shipping multimodal features that look solid in demos, then die the moment a user asks for “same thing, but with one extra constraint.” Benchmarks like this push evaluation toward that real failure mode. If GENIUS catches on, it becomes a forcing function: you either improve controllability, or your model looks dumb in public.
🚀 Reinforcement Learning
Data-Efficient Hierarchical Goal-Conditioned Reinforcement Learning

The Rundown
NF-HIQL swaps simple Gaussian policies for normalizing-flow policies at both hierarchy levels, aiming for better offline/data-scarce performance on long-horizon tasks.
The details
- Introduces Normalizing flow-based hierarchical implicit Q-learning (NF-HIQL).
- Replaces unimodal Gaussian policies with expressive flows (high-level + low-level), while keeping tractable log-likelihood and efficient sampling.
- Adds theory: explicit KL bounds for RealNVP policies + PAC-style sample-efficiency results (as stated in the abstract).
- Evaluates on long-horizon tasks (locomotion, ball-dribbling, multi-step manipulation) and reports stronger robustness under limited data; notes “IEEE ICRA 2026” in comments.
Why it matters
Hierarchical RL often fails in practice because the policy class is too simple for messy multimodal behavior. Flow policies are a direct attack on that bottleneck. If the reported robustness holds up across more settings, this is the kind of change that makes offline robotics training feel less like gambling.
Related Articles
Feb 24
AI Research Rundown: Satellite Detection, VR Simulation, and Legal Predictions
Key insights from the latest papers on AI advancements.
Feb 23
AI Research Rundown: Enhancements in Adversarial Attacks and Reinforcement Learning
Key insights from the latest papers on AI advancements.
Feb 22
AI Research Rundown: Time Series, Adversarial Attacks, and Formula Recognition
Key insights from the latest papers on AI advancements.